Pierluigi Crescenzi1
Emanuele Natale2
Aurora Rossi2
Paulo Bruno de Sousa Serafim1
1Gran Sasso Science Institute
2COATI, INRIA d’Université Côte d’Azur
Summary
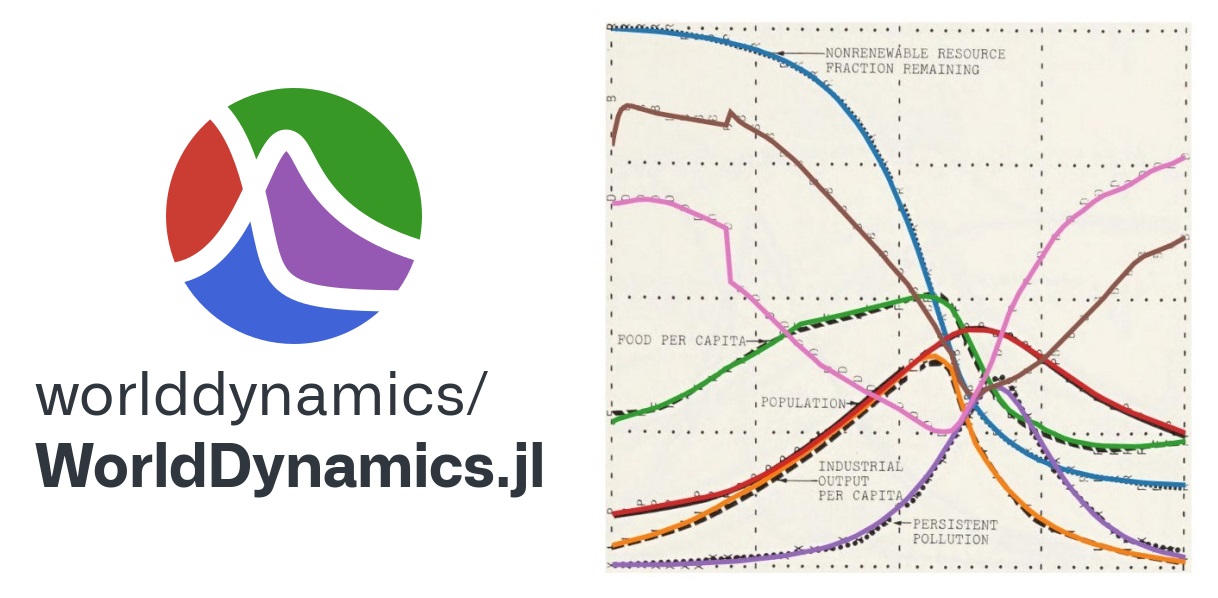
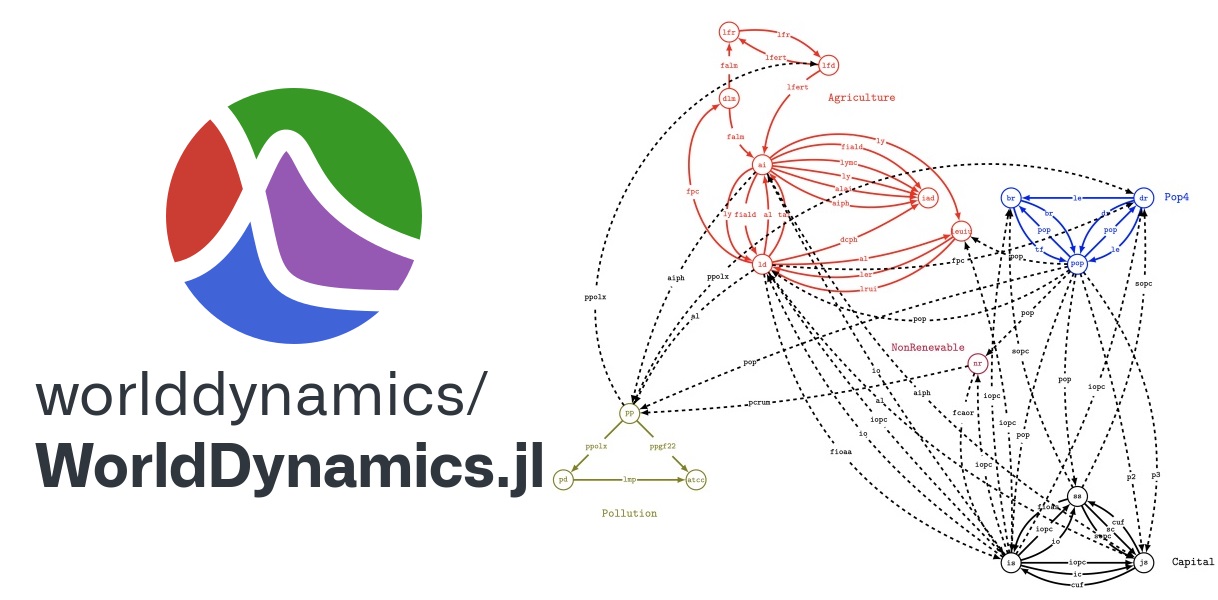
WorldDynamics.jl is an open-source package for the Julia programming language that provides a modern framework for developing, simulating, and investigating Integrated Assessment Models (in short, IAMs). IAMs are numerical models that estimate possible scenarios for the evolution of human society with respect to fundamental aspects such as capital investment, food production, natural resources, population size, and pollution, among others. The current version of the package implements the family of IAMs developed by the Club of Rome, which is a non-profit, informal organization of intellectuals and business leaders dedicated to the critical discussion of pressing global issues. In particular, the library includes Forrester’s World1 and World2 models, the influential World3 model of D. L. Meadows et al. (1974), and its 1994 and 2003 updated versions. These models are typically structured into several sectors, which are, in turn, composed of several differential-algebraic systems of equations (in short, DAEs): this modular structure makes it easy to manipulate the sectors individually and to combine different DAEs into a unique model. The package benefits from Julia’s scientific computing ecosystem, in particular from the efficient solver implementations for various differential equations provided by the DifferentialEquations.jl package and from the ability of the ModelingToolkit.jl package to compose differential-algebraic equations. WorldDynamics.jl provides also several support functions, which allowed us to convert the original systems of finite-difference equations into DAEs and to easily replicate all the plots included in the above-mentioned references. It also allows the possibility of easily changing the parameter values and the systems of equations in order to simulate different scenarios. In other words, WorldDynamics.jl facilitates the use of advanced scientific computing approaches for both classical and new models.
BibTeX
@article{crescenzi2024worlddynamics,
title = {WorldDynamics.jl: A Julia Package for Developing and Simulating Integrated Assessment Models},
author = {Crescenzi, Pierluigi and Natale, Emanuele and Rossi, Aurora and Serafim, Paulo Bruno Sousa},
journal = {Journal of Open Source Software},
year = {2024},
publisher = {The Open Journal},
volume = {9},
number = {95},
pages = {5772},
doi = {10.21105/joss.05772}
}